INVESTIGACI├ōN
Visi├│n artificial e inteligencia artificial: El INAUT desarrolla un m├®todo ultraveloz para optimizar el control de calidad en la producci├│n industrial continua
El Instituto de Autom├Ītica (INAUT, CONICET-UNSJ), en cooperaci├│n con universidades de Ecuador y Colombia, desarroll├│ un m├®todo de visi├│n artificial que optimiza el control de calidad industrial continua en tiempo real. Mediante el uso conjunto de histogramas de color de alta selecci├│n y An├Īlisis de Componentes Principales, el sistema alcanza un 97,22% de precisi├│n en la detecci├│n de fallas de empaque en la industria farmac├®utica, reduciendo dr├Īsticamente el tiempo de procesamiento t├®cnico.
{kind=link}
En el marco de la cuarta revoluci├│n industrial, los sistemas de producci├│n en masa y de flujo continuo exigen mecanismos de monitoreo cada vez m├Īs sofisticados, capaces de realizar inspecciones detalladas y diagnosticar anomal├Łas en los productos finales de manera inmediata. Cuando los flujos operativos funcionan a velocidades sumamente elevadas, confiar la supervisi├│n al ojo humano resulta ineficiente, costoso e incluso inviable para resguardar la seguridad. Frente a este panorama, las l├Łneas de investigaci├│n enfocadas en la inteligencia artificial, el modelado y control de procesos, y los sensores y procesamiento de se├▒ales cobran un rol protag├│nico para automatizar las decisiones de aceptaci├│n o rechazo de productos defectuosos dentro de las plantas fabriles.
Con el prop├│sito de superar las limitaciones actuales del procesamiento visual en entornos de alta velocidad, el equipo de investigaci├│n del Instituto de Autom├Ītica (INAUT) ŌĆöinstituci├│n de doble dependencia entre el Consejo Nacional de Investigaciones Cient├Łficas y T├®cnicas (CONICET) y la Universidad Nacional de San Juan (UNSJ)ŌĆö desarroll├│ una metodolog├Ła innovadora orientada a la detecci├│n temprana de fallas en sistemas continuos. Este tipo de procesos, caracter├Łsticos de sectores sensibles como el farmac├®utico o el de empaque, operan de forma ininterrumpida y demandan respuestas en tiempo real que no generen retrasos ni cuellos de botella en la cadena log├Łstica. Cualquier demora en el diagn├│stico de una anomal├Ła puede provocar la propagaci├│n de fallas, interrupciones en la l├Łnea de montaje e importantes p├®rdidas econ├│micas. El nuevo desarrollo del INAUT busca precisamente mitigar estos riesgos mediante una arquitectura de inspecci├│n automatizada sumamente equilibrada entre precisi├│n y velocidad de respuesta.
Innovaci├│n metodol├│gica: Combinando histogramas y reducci├│n de dimensionalidad
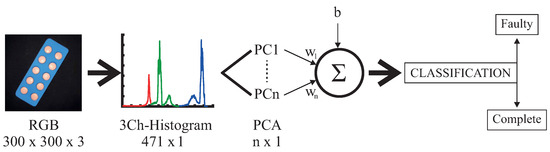
La principal fortaleza cient├Łfica de la propuesta radica en la integraci├│n inteligente de herramientas consolidadas del procesamiento de datos, evitando recurrir a arquitecturas complejas que demandan un costo computacional y de memoria excesivo. El m├®todo comienza capturando im├Īgenes digitales de los productos en la l├Łnea de producci├│n. A partir de all├Ł, el sistema extrae de forma automatizada los histogramas de intensidad de los tres canales de color (RGB) de cada imagen. Los investigadores identificaron un aspecto clave para optimizar el algoritmo: la parte inferior del histograma correspond├Ła exclusivamente a los p├Łles del fondo negro sobre el cual se examinaban los objetos, por lo que carec├Ła de valor informativo. Al descartar ese sector y concentrarse ├║nicamente en la secci├│n superior del espectro de color (los primeros 157 puntos de datos por canal), redujeron dr├Īsticamente el volumen de datos redundantes sin perder rigurosidad anal├Łtica.
Una vez concatenados estos vectores en una representaci├│n combinada de 471 elementos, se aplica la t├®cnica de An├Īlisis de Componentes Principales (PCA) para disminuir a├║n m├Īs la dimensionalidad de la informaci├│n. El estudio demostr├│ que al proyectar los datos de alta dimensi├│n de los histogramas en un espacio de pocas dimensiones, la variabilidad del conjunto original se mantiene casi intacta. Por ejemplo, utilizando ├║nicamente las dos dimensiones correspondientes a los componentes principales m├Īs representativos, se logra conservar el 88,76% de la variabilidad de los datos, permitiendo representar matem├Īticamente cada imagen compleja como un simple punto en un plano bidimensional. Posteriormente, para efectuar la clasificaci├│n final entre productos correctos y defectuosos, se entrena una M├Īquina de Vectores de Soporte (SVM) lineal, que act├║a como un clasificador geom├®trico simple y eficiente que requiere un volumen de datos de entrenamiento sumamente acotado comparado con otros modelos tradicionales de aprendizaje autom├Ītico.
Resultados experimentales y validaci├│n en la industria farmac├®utica
Para comprobar la viabilidad operativa del sistema, el m├®todo fue evaluado rigurosamente utilizando un banco de im├Īgenes destinado al control de calidad de bl├Łsteres de p├Łldoras en procesos industriales. El set experimental consisti├│ originalmente en registros de un bl├Łster azul con diez p├Łldoras circulares de color rosa claro, capturados a una distancia fija de 20 cent├Łmetros mediante un ├Īngulo cenital y bajo condiciones de iluminaci├│n controladas. Debido al n├║mero inicial de muestras y para elevar la robustez del modelo frente a perturbaciones reales de una f├Ībrica, el equipo de cient├Łficos implement├│ un riguroso proceso de aumento de datos ("data augmentation") multiplicando por seis el corpus visual hasta alcanzar las 468 im├Īgenes totales. Este procedimiento incluy├│ transformaciones geom├®tricas como rotaciones verticales y horizontales, la simulaci├│n de variaciones lum├Łnicas mediante m├Īscaras de gradiente de intensidad y la inyecci├│n intencional de ruido gaussiano y de tipo "sal y pimienta".
El modelo clasificador final fue entrenado bajo un esquema binario, agrupando las im├Īgenes en dos categor├Łas bien definidas: "normal" para los bl├Łsteres completos y "defectuoso" para aquellos a los que les faltaba una o dos p├Łldoras. Mediante una validaci├│n cruzada de cinco iteraciones ("5-fold cross-validation"), donde el 80% de los datos se destinaron al entrenamiento y el 20% restante a la validaci├│n, la configuraci├│n que utiliz├│ 50 componentes principales aplicados a la parte superior del histograma alcanz├│ una exactitud sobresaliente del 97,22%. En las pruebas comparativas con otros clasificadores de vanguardia de la literatura cient├Łfica, como HOG combinada con SVM (82,22% de precisi├│n) o PCA combinado con el algoritmo de vecinos m├Īs cercanos KNN (62,50%), el m├®todo propuesto por el INAUT demostr├│ una superioridad notable tanto en precisi├│n como en tiempos de ejecuci├│n, requiriendo apenas 120,6 milisegundos para el entrenamiento y unos asombrosos 0,721 milisegundos para clasificar cada producto en tiempo real.
Este trascendental avance cient├Łfico reafirma el prestigio del INAUT en la vanguardia de la ingenier├Ła y fue posible gracias a una estrecha cooperaci├│n internacional. El trabajo de investigaci├│n fue desarrollado de manera conjunta por los cient├Łficos Rodrigo Gimenez-Valenzuela, Flavio Capraro y Daniel Pati├▒o del INAUT (CONICET-UNSJ), en colaboraci├│n con Julio Montesdeoca de la Universidad Polit├®cnica Salesiana de Ecuador y Brayan Saldarriaga-Mesa, investigador vinculado tanto al instituto sanjuanino como a la Universidad de los Llanos de Colombia. La simplicidad del dise├▒o metodol├│gico abre las puertas a su implementaci├│n directa en dispositivos de procesamiento local en los extremos de la l├Łnea de producci├│n ("edge computing"), consolidando la vinculaci├│n entre la ciencia b├Īsica y el sector productivo global.
DOI: https://doi.org/10.3390/automation7010009